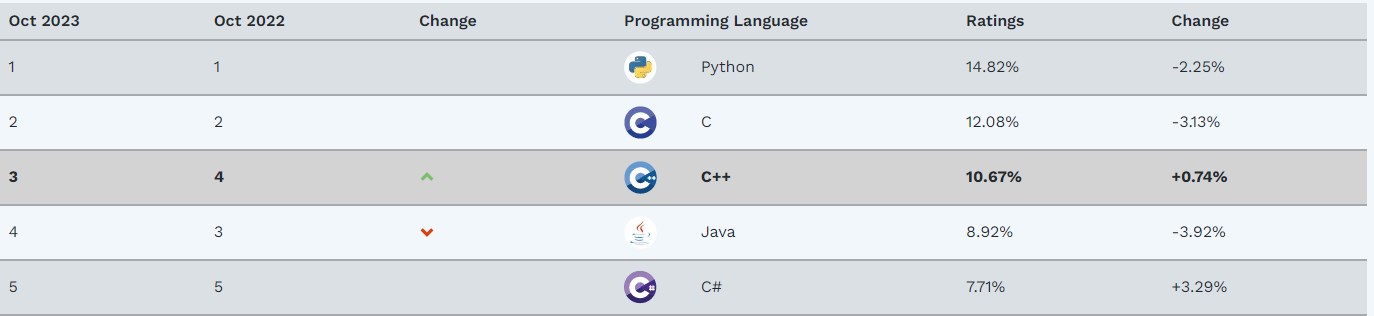
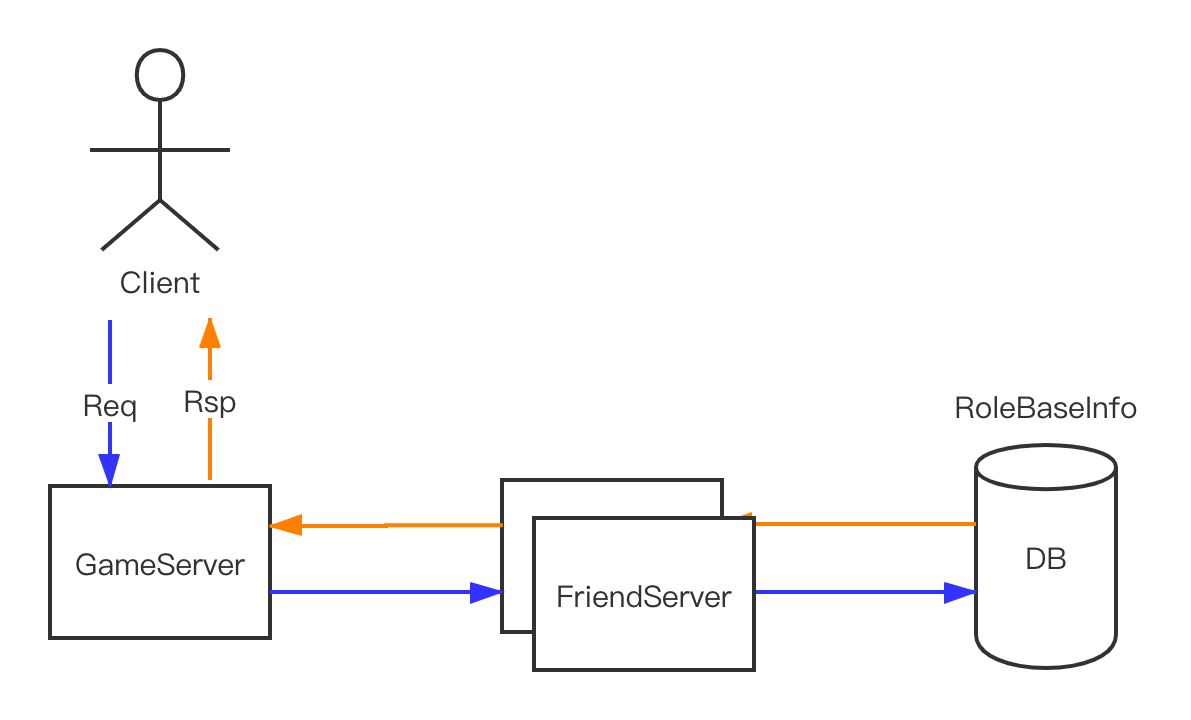
(本文样例和背景基于C/C++/Golang编译出的二进制产物)
当使用二进制编译产物的服务器程序版本有迭代时,一般会按照这样的步骤操作更新: [程序停止]->[更新二进制]->[程序启动] 。排除使用动态库的更新机制,流程可以覆盖基本90%以上的场景。
但在实际的生产环境中并不是简单的[程序停止]->[更新二进制]->[程序启动]这么直接的流程,根据具体业务会有比较多需要注意和处理的细节,描述这些细节有一个比较精确的术语叫:优雅重启。
针对不同的业务,优雅重启的思路也不相同,就我个人经历且实操过的方案而言,优雅重启主要需要考虑以下几个方面的问题:
- 被更新进程退出前的资源处理,包括:内存数据是否回写数据库或者存盘,TCP链接是否有重连机制,程序内部队列的处理,还有在等待回调逻辑是否需要处理;
- 被更新进程在链路中所处位置评估,包括:上下游的依赖情况,更新是否会导致其他模块异常或者服务降级,若发生异常是否能自愈(开发时就应该提前评估好),上游若有队列确保不丢消息。根据服务业务不同,少数情况需要进入业务层定制处理方式;
- 评估进程停启过程需要时长所带来的影响,比如:3s、30s这二个不同停启时长的程序在处理上会完全不一样;(注意这个是停止到启动整体时间,因为在进程收到停止信号时就已经“拒绝服务“准备退出了,退出前的资源处理也需要时间)
整体而言没有一个万金油的方案,部分场景会有较为通用的方案,比如队列、TCP链接重连机制。对于大多数其他问题,不同的业务场景有不同的解法。解法的核心围绕这2个关键词:状态、停启时长。
本文围绕状态与停启时长聊聊几种典型更新方式的方案原型:
Read More →