在多线程编程环境中,有时为了保证数据处理的效率会使用一些无锁(Lockfree)的数据结构,例如无锁队列(Lockfree Queue)、无锁栈(Lockfree Stack)、环形缓冲(Ring Buffer)、无锁哈希(Lockfree Hash)之类。本文分析Boost库(V1.57.0)中的无锁队列,并将其从复杂的Boost数据结构中剥离出来单独实现。
std::memory_order一些用在本文的知识点
参考文献:http://wilburding.github.io/blog/2013/04/07/c-plus-plus-11-atomic-and-memory-model/
http://bartoszmilewski.com/2008/12/01/c-atomics-and-memory-ordering/
编译器从计算机的远古时代发展至今,已经单纯脱离原始的翻译代码,而是会进行非常多的优化,将“糟糕”的代码改写成高效的代码,在多线程环境下会导致指令重排序happens-befors问题std::memory_order作用就是告诉编译器哪些数据是线程共享的,编译器只在必要的情况下对其保守优化。
enum memory_order {
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst};
尽量用一句话在简明概括一下上面每条枚举的用处:
memory_order_relaxed – 不保证顺序性,只保证原子性和修改的一致性。
memory_order_consume – memory_order_acquire弱化版,C++专家特性,一般用不到。
memory_order_acquire – 不会把其他读操作移动它前面,保证读取到(其他线程store(memory_order_release))最新修改。
memory_order_release – 不会把其他写操作移动它后面,保证其他线程(load(memory_order_acquire))可以取到最新修改。
memory_order_acq_rel – 用在对内存值本身操作上,内置acquire/release合体。
memory_order_scq_cst – memory_order_acq_rel强化版,支持处理顺序一致性,最容易用的默认参数。
刚开始提到的memory_order那几个枚举就是告知编译器数据是在线程间共享的,并且是怎样共享的。memory_order_acquire和memory_order_release的关系大概就像mutex的acquire(lock)和release(unlock)。mutex使线程间串行执行,并且上一个线程unlock后另一个线程lock进入,保证可以看到上一个线程的所有数据修改而不会有读写操作被reorder后出问题的情况。
无锁队列Boost库Push的源码和注释
template <bool Bounded>;
bool do_push(T const & t)
{
using detail::likely;
node * n = pool.template construct<true, Bounded>(t, pool.null_handle());
handle_type node_handle = pool.get_handle(n);
if (n == NULL)
return false;
for (;;) {
tagged_node_handle tail = tail_.load(memory_order_acquire);
node * tail_node = pool.get_pointer(tail);
tagged_node_handle next = tail_node->next.load(memory_order_acquire);
node * next_ptr = pool.get_pointer(next);
tagged_node_handle tail2 = tail_.load(memory_order_acquire);
//进行比较是为了防止其他线程进行Push导致了tail变化
//内存模型memory_order_acquire保证tail,tail2取值的顺序性
if (likely(tail == tail2)) {
//Tail.next必须指向0才进行push下一步关键操作
//若不为0,可能另外一个线程提前push,我们进入else将Tail指向Tail.next
if (next_ptr == 0) {
tagged_node_handle new_tail_next(node_handle, next.get_next_tag());
//这里next一般指向0,尝试将Tail.next赋值成新node.next的数值
//若是第一个push node那么Head.next也会改变
//赋值的目的是为了将新node与原有node形成链状关系
if ( tail_node->next.compare_exchange_weak(next, new_tail_next) ) {
//成功赋值,将Tail前移(指向新node)
tagged_node_handle new_tail(node_handle, tail.get_next_tag());
tail_.compare_exchange_strong(tail, new_tail);
return true;
}
}
else {
//移动Tail
tagged_node_handle new_tail(pool.get_handle(next_ptr), tail.get_next_tag());
tail_.compare_exchange_strong(tail, new_tail);
}
}
}
}
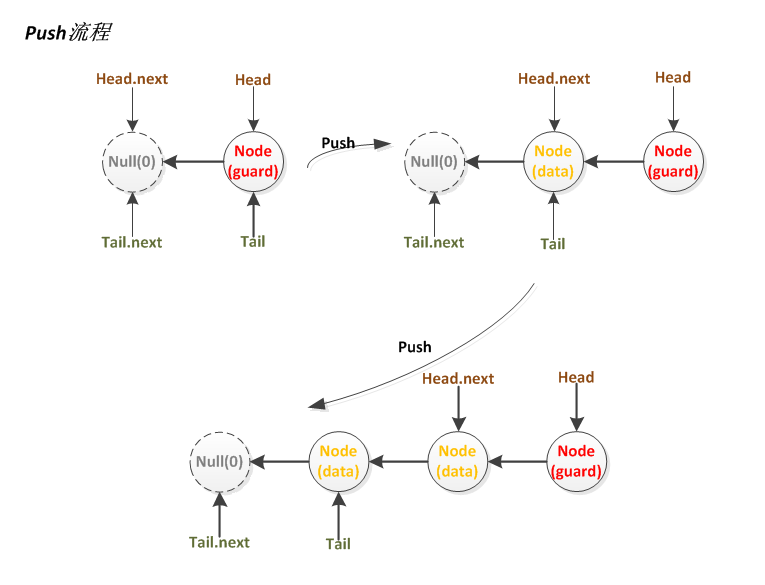
Push图示
无锁队列Boost库Pop的源码和注释
template <typename U>
bool pop (U & ret)
{
using detail::likely;
for (;;) {
tagged_node_handle head = head_.load(memory_order_acquire);
node * head_ptr = pool.get_pointer(head);
tagged_node_handle tail = tail_.load(memory_order_acquire);
tagged_node_handle next = head_ptr->next.load(memory_order_acquire);
node * next_ptr = pool.get_pointer(next);
tagged_node_handle head2 = head_.load(memory_order_acquire);
//进行比较是为了防止其他线程进行Pop导致了head变化
//内存模型memory_order_acquire保证head,head2取值的顺序性
if (likely(head == head2)) {
//头尾一致
if (pool.get_handle(head) == pool.get_handle(tail)) {
//下一个node为0,证明没有可以pop的node
if (next_ptr == 0)
return false;
//还有可以pop的node我们先移动tail
//这里可能出现的情况是有node在其他线程快速push进来
tagged_node_handle new_tail(pool.get_handle(next), tail.get_next_tag());
tail_.compare_exchange_strong(tail, new_tail);
} else {
if (next_ptr == 0)
/* this check is not part of the original algorithm as published
* by michael and scott
*
* however we reuse the tagged_ptr part for the freelist and clear
* the next part during node allocation. we can observe a null-pointer here.
* */
continue;
//取出赋值,这里需要注意的是Head永远是用作哨兵,实际有意义数据的节点是Head.next
detail::copy_payload(next_ptr->data, ret);
tagged_node_handle new_head(pool.get_handle(next), head.get_next_tag());
//为了防止这个节点已经被其他线程pop
if (head_.compare_exchange_weak(head, new_head)) {
pool.template destruct<true>(head);
return true;
}
}
}
}
}
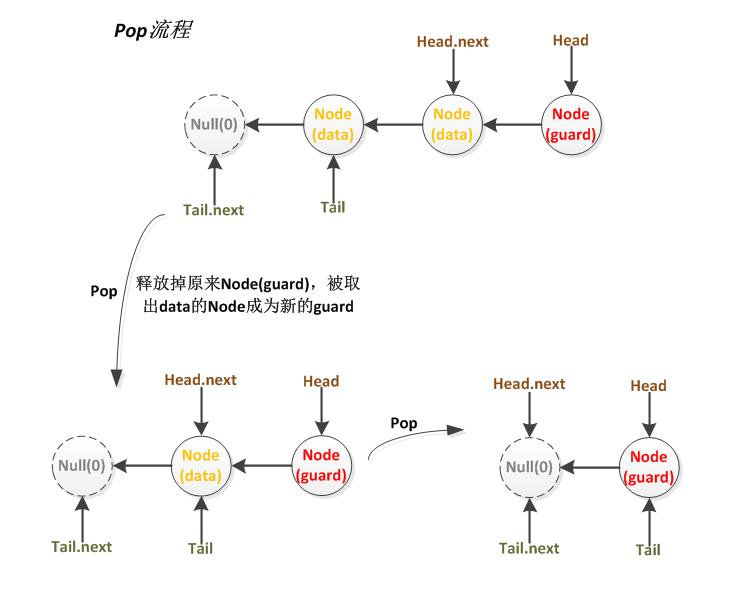
Push图示
点击查看 – 改写的源码
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com
1 Trackback