一篇迟来的文章,这个问题先在公司内部做了分享,然后才搬运到博客上面来。
2020年4月底《山海镜花》开服即炸服,随后玩家串号。作为一个游戏开发者,客观评估串号应该在网游事故中排第三。
个人心中的网游事故排名(同一量级下):
- 玩家数据损坏或者丢失;
- 游戏漏洞导致活动或者道具被刷,毁坏了游戏经济数值系统;
- 串号;
一二可能相对比较好理解,串号这个东西比较玄乎,为什么玩家A会登陆到玩家B账号上面进行操作?甚至连开发同学可能对这个问题开始都是一脸懵:怎么会这样?下面我们逐一来分析串号问题。
(所有分析站在全局角度,并不仅仅针对《山海镜花》的问题)
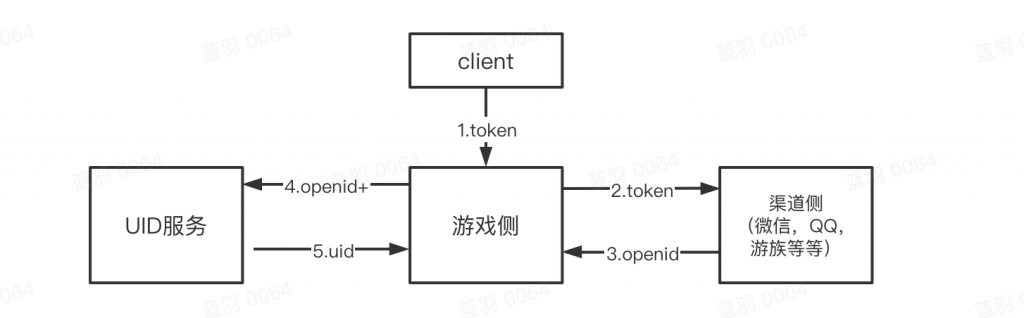
游戏账号怎么确定唯一性?
首先我们明确几个概念:
- openid : 渠道侧对某一用户的唯一标识码;
- uid : 游戏侧对某一用户的唯一ID;
登陆过程一般是先去渠道拿 openid ,然后再去游戏侧内部服务根据一定规则换取 uid 。如果游戏侧使用自己的账号系统,可能流程细节上会有些许区别,但是大体是相通的。
串号是怎么回事?
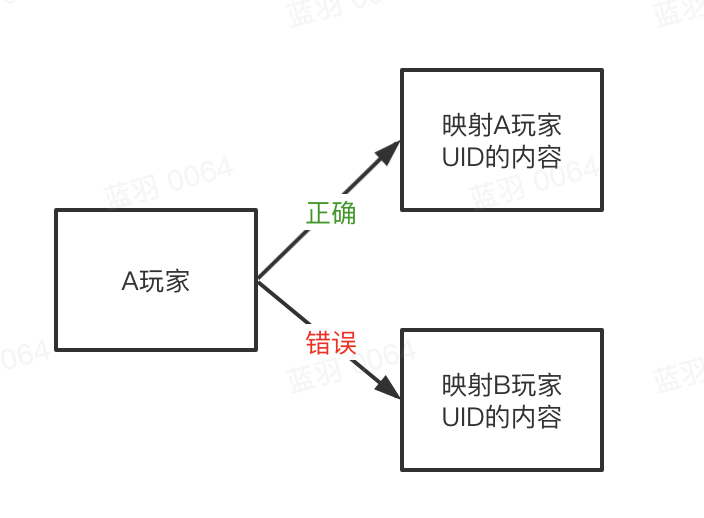
玩家的uid和玩家数据是一一绑定的, 串号简单来说就是A玩家获取到了B玩家的uid,然后用了B玩家的数据登陆:
什么导致了串号?
这个问题的本质就是: 为什么A玩家能获取到B玩家的uid -> 因为uid数据乱了 -> 什么导致了uid混乱?
分析一:uid生成回滚(重复)
在选用uid生成方式合适的情况下,uid是不可能重复生成的。如果存在重复生成,可能的一些假设(需同时成立):
- uid生成不随自然时间递增;
- 在uid生成的时候不是逐条写db的,而是一定时间间隔批量写db;如果uid生成进程在存储间隔期服务跪了,那么内存里的内容也消失了;
- uid生成进程重启之后,uid生成会回滚(重复);
可以运行下面代码观察一下,然后Ctrl+C杀死进程,再运行,会发现每次数据的起始点是一样的(进行了回滚)
//代码只是为了演示回滚的概念,并不做实际产生uid的用途
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
for(;;) {
printf("%d\n", rand());
sleep(1);
}
return 0;
}
分析二:uid获取混乱
- 多线程: 多线程因为临界区保护不合理导致数据混乱是一个经典的问题。若生成uid场景使用多线程,同时uid逻辑临界区保护不合理,在极端情况下会有少量用户uid混乱。如果测试比较完备,这个问题应该会被提早发现。
- 工具使用不当: 一般是开发在使用各种库或者工具没顾及到的问题,问题一般比较隐蔽比较难以排查,需要一些经验的沉淀可能才能避免踩坑,当然也可以说是库或者工具没做好:D。
这里举一个例子, 比如redis的c语言客户端hiredis。 在使用hiredis pipeline的时候,使用redisAppendCommand这一族的函数会把请求内容写入redisContext->obuf,但是在出错返回的时候hiredis并没有把obuf清空,如果使用者不做处理,那么可能会导致下次请求内容数据混乱 。(道听途说《山海镜花》疑似是类似的问题)。
怎么避免串号?
- 关键uid数据需要逐条写入db逐条判断返回,并且对超时和其他异常要有容错处理,不要悬在内存里为了提高效率批量处理,最差也要写下共享内存;
- 对于uid生成,建议和时间关联,这样uid不会回滚而且肯定是递增的。这样做有两个优势:一是对各类时间排序需求友好,二是能提早发现问题。 推荐 Twitter-SnowFlake算法 ,这个算法需要额外关注一下时间回溯的处理;
- 如果有使用多线程,一定要在密集的压力测试下保证数据都是受临界区保护;
(全文结束)
转载文章请注明出处:漫漫路 - lanindex.com